Use Big Query to aggregate data to find ranking
Table of Contents
- The problem
- Conclusion
The problem
Recently, have to resolve below sample data to find ranking per each type, thought of share this, it might have other ways of achieve this but below is what I come out with for how to resolve this problem in SQL.
Below is the sample data to describe this problem.
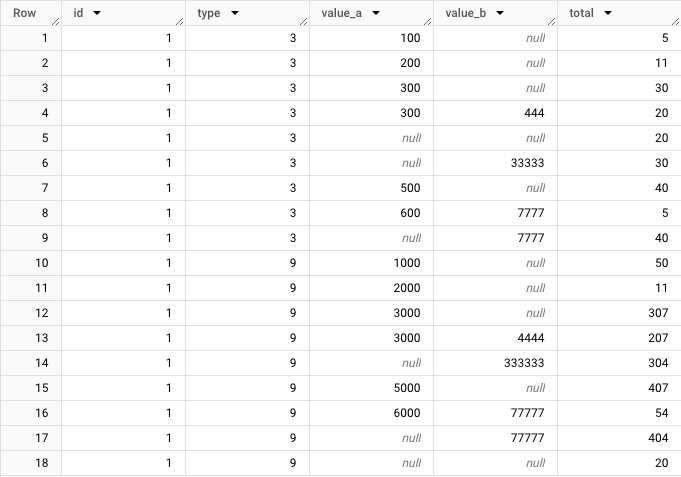
So for instance, for the type 3, the first should be 300 because total is 50, and the rest of the order should be below, also exclude the null.
- 300 -> 50
- 7777 -> 45
- 500 -> 40
- 33333 -> 30
- 200 -> 11
- 100 -> 5
Same as for the type 9, the order should be below, also ignore the null as well.
- 3000 -> 514
- 77777 -> 458
- 5000 -> 407
- 3000 -> 304
- 333333 -> 304
- 1000 -> 50
- 2000 -> 11
Below is the BQ Script actual solve this problem, ideally just find the duplicate count for either of the column, value_a or value_b, then group data set for value_a and value_b and join the data, finally remove the target duplicate value_a or value_b
with sample_data as (
select 1 id, 3 as type, 100 value_a, null value_b, 5 total
union all
select 1 id, 3 as type, 200 value_a, null value_b, 11 total
union all
select 1 id, 3 as type,300 value_a, null value_b, 30 total
union all
select 1 id, 3 as type,300 value_a, 444 value_b, 20 total
union all
select 1 id, 3 as type,null value_a, null value_b, 20 total
union all
select 1 id, 3 as type,null value_a, 33333 value_b, 30 total
union all
select 1 id, 3 as type,500 value_a, null value_b, 40 total
union all
select 1 id, 3 as type,600 value_a, 7777 value_b, 5 total
union all
select 1 id, 3 as type,null value_a, 7777 value_b, 40 total
union all
select 1 id, 9 as type, 1000 value_a, null value_b, 50 total
union all
select 1 id, 9 as type, 2000 value_a, null value_b, 11 total
union all
select 1 id, 9 as type,3000 value_a, null value_b, 307 total
union all
select 1 id, 9 as type,3000 value_a, 4444 value_b, 207 total
union all
select 1 id, 9 as type,null value_a, 333333 value_b, 304 total
union all
select 1 id, 9 as type,5000 value_a, null value_b, 407 total
union all
select 1 id, 9 as type,6000 value_a, 77777 value_b, 54 total
union all
select 1 id, 9 as type,null value_a, 77777 value_b, 404 total
union all
select 2 id, 3 as type,10 value_a, null value_b, 5 total
union all
select 2 id, 3 as type,20 value_a, null value_b, 10 total
union all
select 2 id, 9 as type,null value_a, null value_b, 20 total
)
, agg_value_a_duplicate as (
select id, type, value_a, count(value_a) count
from sample_data
where value_a is not null
group by id, type, value_a
having count > 1
)
, agg_value_b_duplicate as (
select id, type, value_b, count(value_b) count
from sample_data
where value_b is not null
group by id, type, value_b
having count > 1
)
, remove_value_b as (
select sample_data.value_b from sample_data
where sample_data.value_a in (
select value_a from agg_value_a_duplicate
)
and sample_data.value_b is not null
)
, remove_value_a as (
select sample_data.value_a from sample_data
where sample_data.value_b in (
select value_b from agg_value_b_duplicate
)
and sample_data.value_a is not null
)
, agg_value_a as (
select id, type, value_a, sum(total) total
from sample_data
where sample_data.value_a is not null
group by id, type, value_a
)
, agg_value_b as (
select id, type, value_b, sum(total) total
from sample_data
where sample_data.value_b is not null
group by id, type, value_b
)
, join_value_a_value_b as (
select id, type, value_a, null as value_b, total from agg_value_a
union all
select id, type, null as value_a, value_b, total from agg_value_b
)
select *
from join_value_a_value_b
where (value_b is null or value_b not in (select value_b from remove_value_b))
and (value_a is null or value_a not in (select value_a from remove_value_a))
order by id, type, total desc
Conclusion
Above script does resolve the issue, but wonder if there's other way?